Honkaku Bench: Are AI Smarter Than Sherlock Holmes?
![]()
Summary
We gave five frontier AI models 70 fair-play murder mysteries — the honkaku genre, where every clue is visible and the reader is challenged to solve the case before the detective does. Then we asked a simple question: can today’s best models actually reason their way to the killer?
Mostly, no.
None of the models, including Claude Fable 5, can solve >20% of the cases perfectly. Even when counting the cases that are only mostly solved, the best model (Fable 5) still only solves about one in three cases. But the real story is not the leaderboard — it is the failure mode. The models usually notice the right clues. However, they still struggle to turn evidence into proof.
Why Honkaku?
Most AI reasoning benchmarks test narrow, well-specified problems: math proofs, code correctness, factual retrieval. Honkaku mysteries test something harder to simulate: multi-step deductive reasoning under ambiguity, where every premise is handed to you in prose and the path from evidence to conclusion is entirely yours to construct.
The genre has four properties that make it unusually good as a benchmark:
- Closed-world guarantees. Every clue needed to solve the case is in the story. There is no hidden information required. A model cannot excuse failure by citing missing information.
- Spatial and visual reasoning. Many cases require more than following a textual argument. The solver must inspect enclosed pictures (layouts of the murder scene, maps, etc.) and infer what must have happened.
- Unique, derivable answers. The author designs the puzzle so exactly one suspect, motive, and mechanism are consistent with all clues. Partial credit is meaningful — you can be right about the culprit and wrong about the method, or correct on both but for the wrong reasons.
- Rich failure signal. When a model fails, the reasoning trace shows where the chain broke — a property not available from multiple-choice benchmarks that reveal only outcome.
Benchmark Setup
70 cases. We source the problems from a privately-held college-level murder mystery competition. All of the problems are verified by experts to be uniquely solvable and none of the problems appears online. The topics of the problems cover locked-room murders, alibi reconstructions, and probability puzzles disguised as mystery fiction.
Models. We select the most frontier LLMs: Claude Fable 5, Claude Opus 4.8, Claude Opus 4.6, GPT-5.5, and Gemini 3.1 Pro. We evaluate the LLM with their official agent harnesses.
Scoring. The submissions are rated directly using the competition’s official scoring criteria. Following the expert-curated and manually-validated point allocation guides, we use Opus 4.8 to rate the correctness of the mechanism, motive, key clue identification, and the deductive steps that connect evidence to conclusion.
Grading the full reasoning chain is the whole point of the benchmark. Since the total number of suspects is usually small (<10 people), the model can guess the correct suspect even with reasonings that are wrong. As we will see later, Opus 4.8 built a confident argument on a connectivity graph leading to the correct murderer of Case 07. However, the argument was wrong from the very beginning.
Key Findings
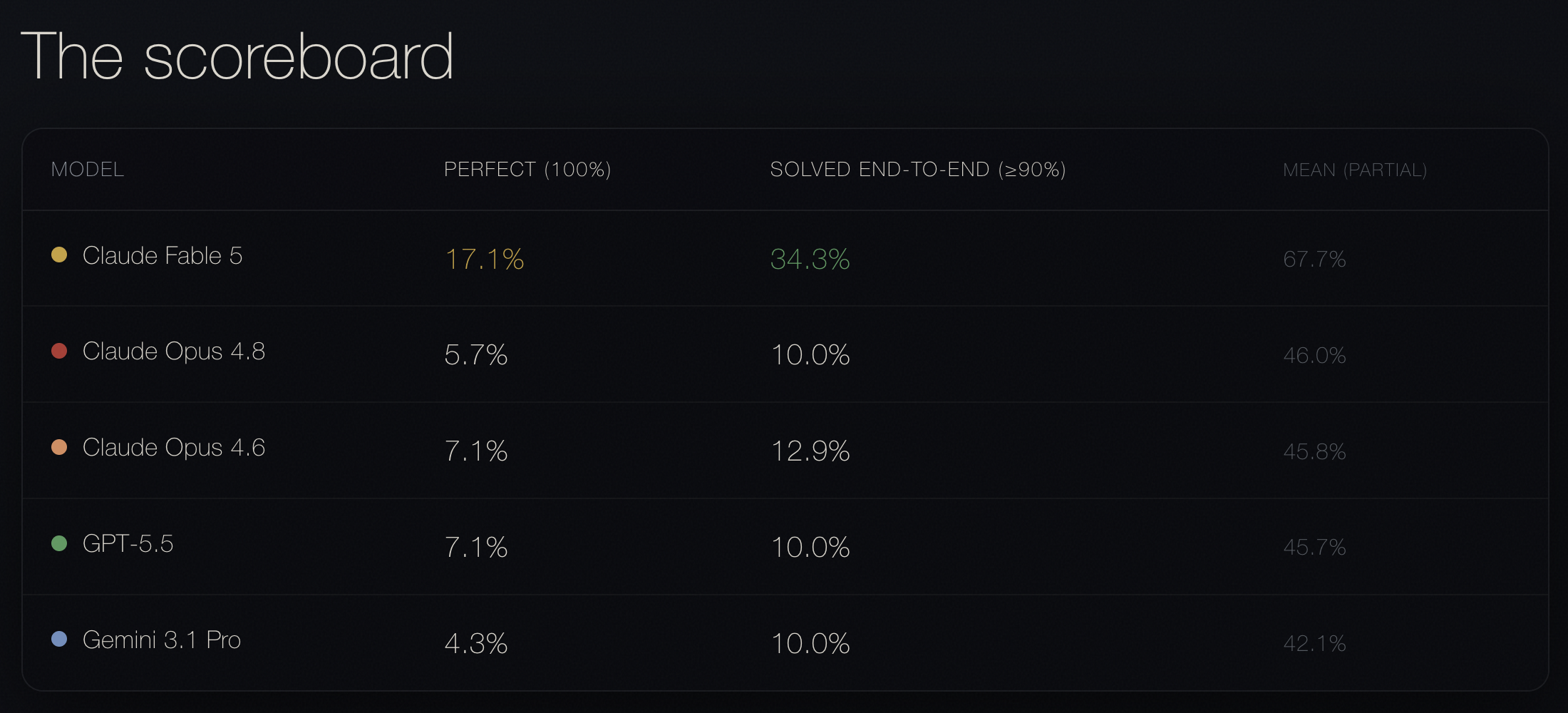
Honkaku Bench remains difficult even for the strongest frontier models. Claude Fable 5 performs best overall. However, even Fable solves only about one third of the cases, leaving most mysteries unsolved despite having access to all necessary clues.
The remaining models are tightly clustered: Claude Opus 4.8, Claude Opus 4.6, GPT-5.5, and Gemini all achieve only ~10% end-to-end solve rates. Current frontier models can often make partial progress, but complete deductive solutions remain rare. Honkaku Bench reveals that there is still a large missing capability in turning evidence into a full, correct explanation.
Three Cases That Explain the Failure Mode
This section contains spoilers. Skip ahead to Try It Yourself if you still want to try the cases out yourself!
Case 07 · “RPG JUMP” — Same clue, opposite reading
Seven temples on a grid map. Every 50 minutes a teleport spell moves every player to the nearest other temple — corpses included. The puzzle hinges entirely on what “nearest” means.
Both Fable 5 and Opus 4.8 identified the same calibration clue: from temple 106, the next jump is equally likely to land on 104, 105, or 107. Opus concluded “nearest = shortest straight-line distance” — literally annotating its own model as “verified correct.” Fable reasoned from the game’s title: in an RPG, movement is four-directional, so distance is Manhattan, not Euclidean. Under Manhattan distance, the three equidistant options hold; under Euclidean, they don’t. Both models then named the same killer. But Opus built its case on a wrong connectivity graph; Fable worked out the one-way temple that can hide a killer and two victims with no witnesses.
Fable 5: 16/18. Opus 4.8: 1/18.
Case 04 · “The Magic Door Murders” — Right clue, wrong mechanism
A sealed bunker has a door that shuts roughly 40 seconds too early each night. Both models caught the threshold insight: a 40-second discrepancy implies a time-zone difference. From there, one model reconstructed the actual mechanism — paired doors across time zones, with an “in-between space” the killer uses to escape the locked room — and correctly eliminated every suspect but one. The other reached the same insight and then improvised a plausible-sounding structure that diverged from the truth, accused the wrong man, and scored 8/20.
The pattern recurs: a model reaches the pivot insight, then narrativizes a confident structure around it instead of grinding through the constraints until one suspect survives.
Fable 5: 20/20. Opus 4.8: 8/20.
Case 08 · “(Not) Random Ball-Drawing” — A flawless proof of the wrong premise
This is the most instructive failure in the dataset, and it belongs to Fable. A probability puzzle whose entire edifice rests on reading two soft, observational clues correctly — what a hand gesture means, and what a girl is wearing. Fable read the gesture as “12” (a class number on a jersey), built a fully self-consistent 12/12/24 ball system, and wrote a program to brute-force-verify that this system satisfied every stated constraint. The logic was airtight. The premise was wrong.
The sub-question that required only deduction and no soft-clue interpretation? Fable scored a perfect 2/2, with reasoning identical to the official solution. Every downstream question then collapsed — each one inherited the misread premise.
Fable 5: 5/19. Opus 4.8: 0/19.
The lesson: the clue that trips you is never a logic step. It is a piece of observational flavor text.
Failure Forensics
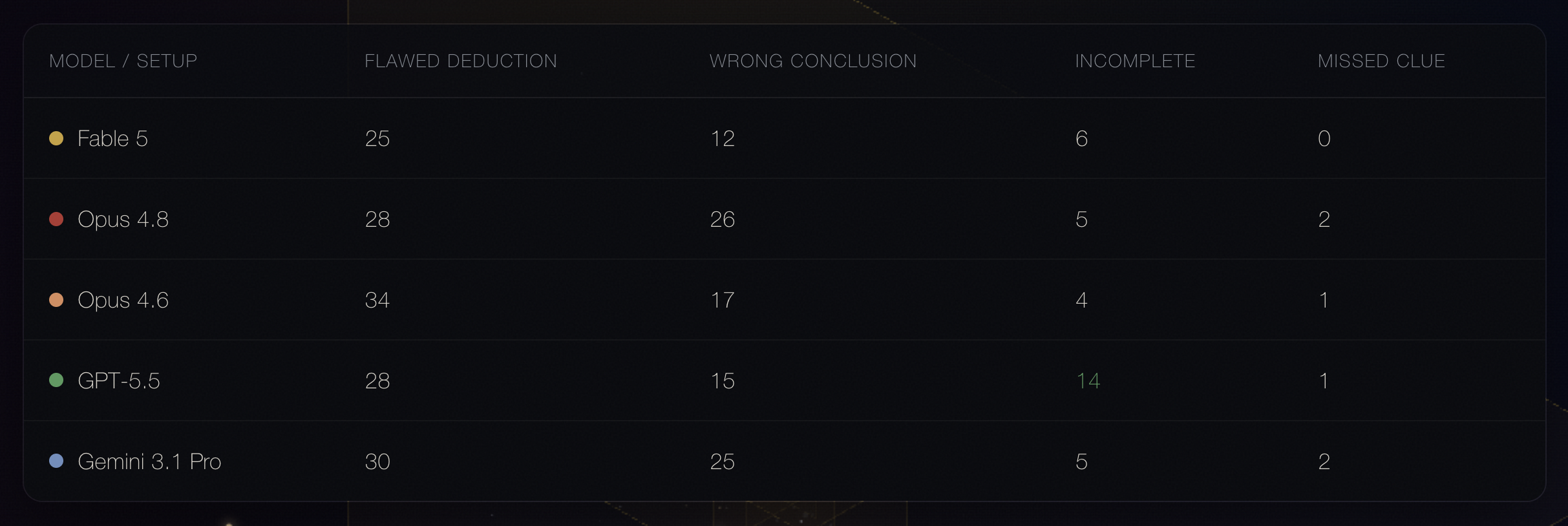
Flawed deduction and wrong conclusion account for the overwhelming majority of failures — typically 80–90% per model. Missed clues are negligible across the board (0–2 cases each). The inference is direct: these models are not losing because they failed to read the evidence. They are losing because their reasoning over that evidence is faulty.
GPT-5.5 is the exception. It logs far more incomplete reasoning failures (14) and correspondingly fewer wrong conclusions. It tends to stop short rather than commit — which is a different failure mode, and in some ways a more cautious one, but it does not produce more end-to-end solves.
Does the Agent Harness Help?
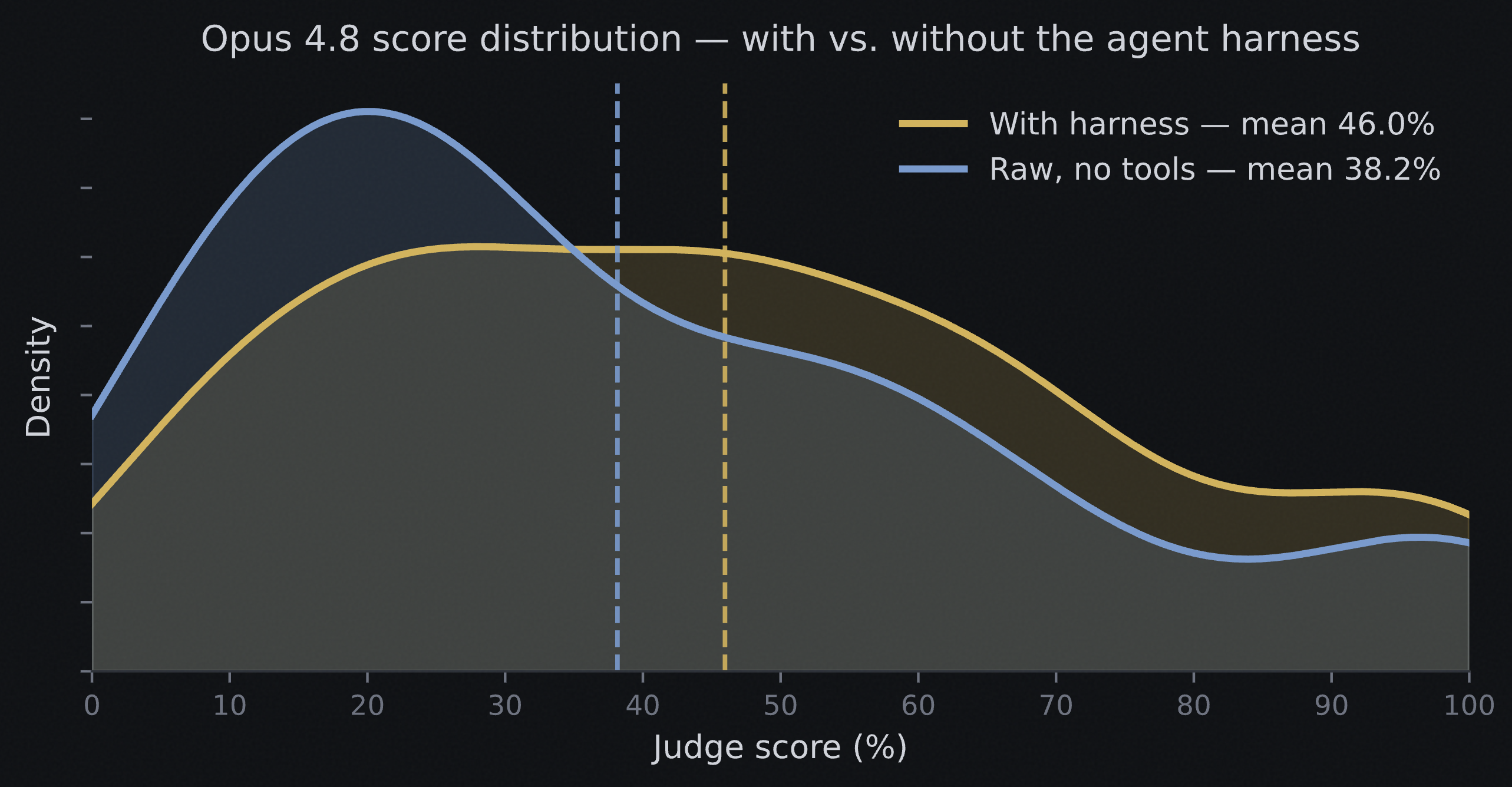
The harness adds 7.8 mean-score points but does not increase the solve rate. Looking at the score distribution, it shifts mass out of the low end (very poor solves) into the middle range — more partial credit, not more complete answers. The mechanism is narrow: on quantitative puzzles, a shell lets the model verify a deduction by running it. In narrative cases, the multi-turn tool loop can talk the model into a wrong frame and score below the one-shot baseline.
What This Tells Us About AI Reasoning
The bottleneck is inference, not retrieval. Every model in this benchmark received the same closed dossier. None of them were operating under information asymmetry. The failures cluster at the stage where a model takes a piece of correctly-seen evidence and builds the wrong structure on top of it — misidentifying the frame, over-committing to the first consistent narrative, or failing to exhaustively check constraints.
Confident wrong reasoning is worse than uncertainty. Opus 4.8 on RPG JUMP explicitly annotated its own Euclidean-distance model as “verified correct.” Case 08 saw Fable write a verifying program for a wrong premise. In both cases, the model’s confidence was the mechanism of failure — it closed off the search once it had a consistent story rather than the consistent story.
The verdict is a terrible proxy for the solve. If you score only on culprit identification, Fable and Opus look tied on RPG JUMP. Score the reasoning and they are 16 points apart. Any benchmark that collapses multi-step reasoning to a binary correct/incorrect is discarding most of its signal.
Broader Implications
The honkaku genre was designed, before AI, to be the purest test of fair-play deduction — no privileged information, no special knowledge, just inference from a fixed evidence base. That it now functions as a discriminating AI benchmark is not a coincidence. It is discriminating for the same reason it is satisfying to human readers: it rewards the one thing that is hard to fake, flawed-deduction analysis, over surface-level pattern matching.
For capability evaluations. Benchmarks that score only final answers, or that aggregate partial credit into a single mean, can produce rankings that do not reflect which models are better reasoners. Honkaku Bench’s solve-rate gap — 34.3% vs. 10% — is invisible in mean scores. If you are choosing a model for a task where the path to the answer matters, you need a benchmark that grades the path.
For benchmark design. The harness experiment is a concrete caution: tool access raises your reported numbers without raising your solve rate. If you report only the harnessed configuration, you will overstate your model’s reasoning capability relative to what it can do in a one-shot setting — which is the setting most deployment scenarios resemble.
For the field. The dominant failure mode — flawed deduction over correctly-seen evidence — is not something retrieval augmentation, larger context windows, or additional tool calls will fix. The ceiling for these models on honkaku is determined by inference quality, not information access. That is both a clear diagnostic and a research direction.
Try It Yourself
Eight cases from the benchmark are publicly available at honkaku-bench.github.io/puzzles.html. Every clue is on the page. No answer key is in sight. You can read a case, submit your reasoning, and see how your deduction compares to the models.
Contact: honkakubench@gmail.com